Segmentierung
Abstract
Jeder, der schon mal in C programmiert hat, wird ihn kennen und vermutlich auch hassen - der "Segmentation Fault". Doch was bedeutet dieser überhaupt und wieso tritt dieser so oft auf? All das werden wir in diesem Post klären.
Info: Die Informationen aus diesem Post stammen fast ausschließlich aus dem grandiosen Buch “Operating Systems - Three Easy Pieces”.
Einleitung
Ein “Segmentation Error” ist ein Fehler, der bei Programmen, die mit C programmiert worden sind, gerne während der Laufzeit auftritt. Er kommt somit oft unerwartet und ist meistens besonders nervig zu finden. Vor allem da man oft gar nicht so wirklich weiß, was dieser Fehler denn nun eigentlich bedeutet. Zumindest ging es mir eine ganze Weile so - bis ich begonnen habe, das grandiose Buch “Operating Systems - Three Easy Pieces” zu lesen. Anfangs eigentlich nur in der Hoffnung, mehr über mein Betriebssystem zu lernen. Dass ich dadurch dann auch endlich ein besseres Verständnis von diesem Fehler bekomme, hatte ich nicht erwartet, aber fand es so cool, dass ich jetzt hier diesen Blog-Post schreibe.
Bevor wir aber jetzt in die eigentliche Thematik einsteigen, hier noch ein kleiner Disclaimer: Ich setze in diesem Artikel gewisse Grundkenntnisse darüber, wie eine CPU funktioniert, voraus. Sollte dir also der Ausdruck “Assembler” nicht sagen, würde ich dir empfehlen, dich zuvor noch ein wenig einzulesen. Es kann durchaus sein, dass ich dieses Thema in naher Zukunft noch hier in meinem Blog behandle. Sollte dies der Fall sein, werde ich hier den Artikel nachträglich verlinken.
Jetzt aber los, wir wollen damit beginnen, eine Abstraktion der auf der CPU laufenden Programme einzuführen:
Prozesse
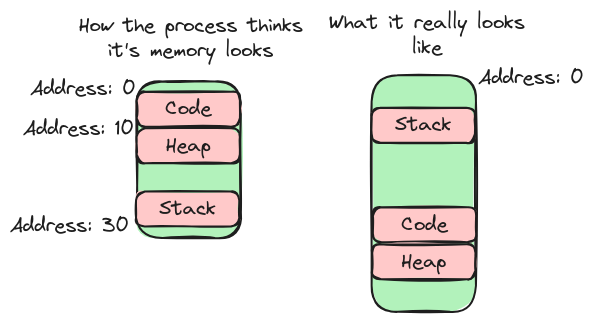
Ein Prozess ist im Endeffekt nichts anderes als ein laufendes Programm. So ist zum Beispiel der Browser, mit dem du diesen Artikel hier gerade liest, der PDF-Viewer, den du vielleicht im Hintergrund geöffnet hast, aber auch das Programm, welches regelmäßig dein E-Mail-Postfach updatet, ein eigener Prozess. Wichtig anzumerken ist hierbei, dass dabei jeder Prozess natürlich etwas RAM-Speicher nutzt, um zum Beispiel die Werte sämtlicher Variablen, die der Programmierer im Code verwendet hat, zu speichern. Konkret hat jeder Prozess dabei genau drei Bereiche, in denen er Daten speichern kann. Den Code-Bereich, den sogenannten Heap-Bereich und den Stack-Bereich. Jeder dieser Bereiche dient dabei der Speicherung von anderen Daten. So wird in dem Code-Bereich der eigentlich auszuführende Code gespeichert, in den Stack werden Dinge wie lokale Variablen oder auch Funktionsargumente gespeichert und in den Heap alle anderen Daten und Datenstrukturen, die ein Programm eben benötigt. Wichtig ist, dass hierbei jeder Prozess seine eigenen drei Bereiche hat. Wär dies nicht der Fall, könnte der CPU irgendwann nicht mehr unterscheiden, welcher Eintrag nun zu welchem Prozess gehört. Werden also jetzt zwei Prozesse gleichzeitig ausgeführt, sieht der RAM stark vereinfacht wie folgt aus.
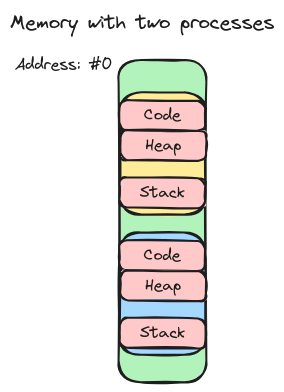
Merke bei dem Bild den Abstand zwischen dem Stack und dem Heap. Dieser ist zwar quasi für den jeweiligen Prozess reserviert, ist aber noch nicht in Benutzung, da sowohl der Heap als auch der Stack-Bereich während der Laufzeit wachsen können. (Der Heap wächst zum Beispiel, wenn man in C mittels malloc() Speicher anfragt.)
Virtualisierung des Speichers
Schön und gut. Es hat also nun jeder Prozess seinen eigenen Bereich im RAM des Computers. Doch ein Problem, das sich dabei ergibt, ist, dass jedes Mal, wenn ein Programm neu gestartet wird, das Betriebssystem den Speicherbereich eines Programmes an einen anderen Ort im RAM legt. Somit beginnt der Code-Block jedes Mal an einer anderen Adresse. Das ist aber ein Problem, denn will man in Assembly eine Funktion aufrufen, so macht man dies einfach, indem man der CPU sagt, sie soll an eine Adresse springen. Doch wie soll der Programmierer der CPU denn sagen, an welche Adresse sie springen soll, wenn sich der Code-Block und somit auch die Funktion jedes Mal an einer anderen Stelle im RAM (also an einer anderen Adresse) befindet?
Da dies so also nicht klappt, hat man sich eine Alternative überlegt. Was, wenn man jedem Prozess vorgaukelt, sein Code-Block beginnt bei Adresse 0? Somit hätte jede Funktion bei jedem Mal ausführen immer wieder die gleiche Adresse und der Programmierer könnte ohne Probleme zu dieser springen.
Diesen Vorgang nennt man Virtualisierung des Speichers. Warum Virtualisierung? Ganz einfach, weil wir den echten RAM-Speicher in viele (für jeden Prozess einen) virtuelle Speicher zerteilen.
Somit ergeben sich dann auch zwei Adressen für jeden Eintrag im RAM. Einmal die sogenannte physikalische Adresse. Dies ist die wirkliche Adresse einer Speicherzelle, also jene Adresse, unter der man im RAM suchen muss, um einen Eintrag zu finden. Zusätzlich ergibt sich dann noch eine virtuelle Adresse. Das ist die Adresse, die der Programmierer denkt, dass ein Eintrag hat. Das folgende Bild dient dazu, das Verständnis noch etwas zu stärken.
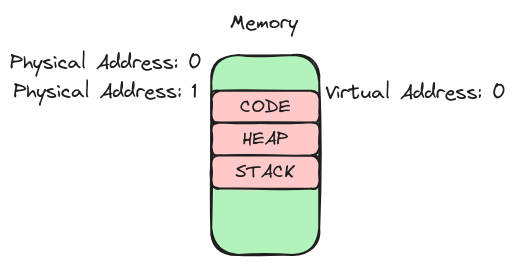 Hierbei sieht man den Speicherbereich eines Prozesses im RAM. Der Code-Block des Prozesses startet hierbei bei der physikalischen Adresse 1 und der virtuellen Adresse 0.
Hierbei sieht man den Speicherbereich eines Prozesses im RAM. Der Code-Block des Prozesses startet hierbei bei der physikalischen Adresse 1 und der virtuellen Adresse 0.
Diese Virtualisierung des Speichers kann man auch live beobachten. Denn jede Adresse, die man jemals von einem C-Programm aus-geprintet bekommt, ist immer eine virtuelle Adresse; der Prozess selbst hat ja keine Ahnung, dass er eigentlich für doof verkauft wird. Die wahre Adresse kennt nur das Betriebssystem und die Hardware selbst. Die beiden sind nämlich dafür zuständig, diese Illusion zu erzeugen.
Address-Translation
Dies machen die beiden durch ein Verfahren, das sich “Address-Translation” nennt. Darunter versteht man im Endeffekt einfach, dass immer, wenn der CPU eine Adresse über den Weg läuft, sie einen Teil der CPU, die sogenannte MMU (Memory Management Unit) befragt, und diese die virtuelle Adresse in eine physikalische umwandelt. Mit dieser kann die CPU dann weiter arbeiten. Dabei gibt es mehrere Algorithmen, die die MMU anwenden kann, um diese Umwandlung durchzuführen. Einer dieser Algorithmen ist die:
Dynamic Relocation
Der Einfachheit halber werde ich bei dieser und auch der folgenden Erklärung annehmen, dass immer nur ein Prozess gleichzeitig läuft. Dies bedeutet dabei allerdings nicht, dass nicht auch andere Prozesse Speicher im RAM beanspruchen. In meiner Erklärung fehlt lediglich ein essenzieller Teil – nämlich die Virtualisierung der CPU – um das Folgende mit gleichzeitig laufenden Prozessen zu verstehen. Am Prinzip ändert dies jedoch nichts, weshalb ich dies lieber so erkläre.
Also, angenommen nun, wir haben einen Prozess, der wie in dem Bild zuvor im RAM liegt, also mit dem Code-Block beginnend bei der physikalischen Adresse 1. Angenommen außerdem, es gibt im Code eine Stelle, an der einfach das gesamte Programm von vorne begonnen werden soll, so hat der Programmierer vermutlich einen Befehl in die Richtung von jmp #0 eingebaut. Also einen Sprung an Adresse 0. Die Adresse ist hierbei aber natürlich eine virtuelle Adresse. Die Adresse, an die die CPU eigentlich springen soll, ist ja die Adresse 1 (dort, wo der Code beginnt). Liest die CPU jetzt den Befehl, so wird diese die MMU benutzen, um die Adresse umzuwandeln. Doch wie passiert diese Umwandlung?
Bei der sogenannten “Dynamic Relocation” werden hierbei zwei Register, also sehr schnelle kleine Speicherzellen, verwendet. Das eine heißt “base” und beinhaltet einfach die physikalische Adresse, an der der Code-Block beginnt. In unserem Fall also die Adresse 1. Das andere Register heißt dann noch “bounds” und beinhaltet die Große des Speicherblocks unseres Prozesses. Besteht also der Code-Block aus 4, der Heap aus 2 und der Stack aus einem Eintrag im RAM, so würde das “bounds” Register die Zahl 7 beinhalten. (Achtung: Diese Zahlen und auch die Adressen sind hierbei natürlich weit weg von der Wirklichkeit, dienen aber der einfacheren Rechnung) Das “bounds” Register ist dabei lediglich hier, um zu prüfen, ob ein Prozess nicht probiert auf eine Adresse außerhalb seines Speicherbereichs zuzugreifen. Man stelle sich bloß vor, was passieren würde, wenn ein jeder Prozess einfach auf den Speicher eines jeden anderen zugreifen und somit auch verändern kann. Das wäre ein reinstes Paradies für jeden Virus, denn der könnte somit unter andrem einfach Passwörter, die noch im RAM liegen auslesen.
Mit diesen beiden Registern kann nun also die MMU die Umwandlung ganz einfach machen. Sie muss dabei lediglich zuerst prüfen, ob die virtuelle Adresse kleiner ist als das “bounds” Register, also ob die virtuelle Adresse noch innerhalb des Speicherbereichs eines Prozesses liegt. Tut sie das, kann die MMU einfach die virtuelle Adresse plus den Wert des “base” Registers rechnen, um somit die physikalische Adresse zu erhalten. In unserem Fall also rechnet sie $0+1=1$, was, eben genau die physikalische Adresse ist, an der der Code-Block beginnt. Hier noch eine Zeichnung, die das Verfahren hoffentlich noch etwas klarer macht.
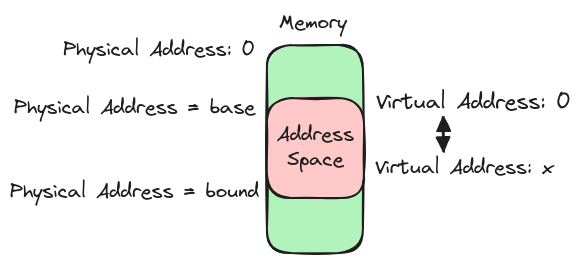 Der Address-Space ist hierbei einfach der Speicherbereich eines Prozesses.
Der Address-Space ist hierbei einfach der Speicherbereich eines Prozesses.
Ein Problem, welches sich allerdings durch dieses Verfahren ergibt, ist der Freiraum zwischen Heap und Stack. Dieser ist wie gesagt derzeit noch für einen Prozess reserviert, jedoch nicht verwendet und somit auch irgendwie verschwändet. Ein Verfahren, das dieses Problem löst und uns auch gleichzeitig die Antwort auf unsere ursprüngliche Frage liefert, ist:
Segmentierung
Segmentierung funktioniert nun ganz ähnlich zu Dynamic Relocation. Anstatt aber nur ein base/bounds Register-Paar pro Prozess zu haben, haben wir hier 3. Eins für das Code-Segment, eins für das Heap-Segment und eins für das Stack-Segment. Dies erlaubt es uns also, die drei Teile, aus denen sich unser Speicherbereich zusammensetzt, separat voneinander in den RAM zu legen. Somit kann zwischen Heap und Stack einfach zum Beispiel das Code-Segment eines anderen Prozesses liegen. Also zum Beispiel so:
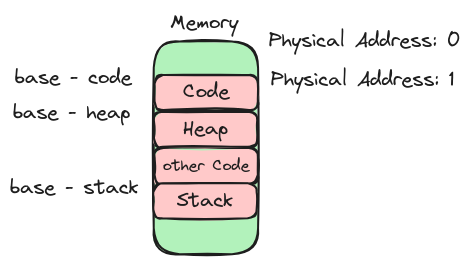 Wichtig hierbei ist, dass der Prozess selber und auch der Programmierer nach wie vor denken, der Speicher im RAM wäre wie gewohnt angeordnet, obwohl er dies absolut nicht sein muss.
Wichtig hierbei ist, dass der Prozess selber und auch der Programmierer nach wie vor denken, der Speicher im RAM wäre wie gewohnt angeordnet, obwohl er dies absolut nicht sein muss.
 Will nun die MMU mithilfe von Segmentierung eine virtuelle Adresse in eine physikalische umwandeln, muss sie lediglich, je nachdem auf welchen Teil des Speicherbereichs(Code, Heap oder Stack) eine virtuelle Adresse zeigt, das richtige base/bounds Paar wählen. Allerdings muss man jetzt aber bedenken, dass man hier nicht mehr einfach $base + virtual = physical$ rechnen kann. Wieso? Na ja, das base Register hat ja in diesem Fall nur mehr im Falle des Code-base Registers die physikalische Adresse der virtuellen Null gespeichert.
Will nun die MMU mithilfe von Segmentierung eine virtuelle Adresse in eine physikalische umwandeln, muss sie lediglich, je nachdem auf welchen Teil des Speicherbereichs(Code, Heap oder Stack) eine virtuelle Adresse zeigt, das richtige base/bounds Paar wählen. Allerdings muss man jetzt aber bedenken, dass man hier nicht mehr einfach $base + virtual = physical$ rechnen kann. Wieso? Na ja, das base Register hat ja in diesem Fall nur mehr im Falle des Code-base Registers die physikalische Adresse der virtuellen Null gespeichert.
Im Falle des Heaps müssen wir also nun zuerst den Abstand der virtuellen Adresse vom Anfang des Heaps errechnen und können so dann das bounds Register prüfen und die Adresse umwandeln. Betrachtet man das Bild oben und wollte eine Adresse 15 in eine physikalische umwandeln, würde die MMU zuerst $15-10=5$ und dann erst $physical = 5 + base_{heap}$ rechnen.
Für den Stack funktioniert die Umwandlung dann wieder ein wenig anders. Dieser wächst nämlich von unten nach oben. Doch da ich darauf hier noch nicht eingegangen bin, will ich dies weglassen. Interessierte sollten allerdings relativ einfach selbst auf eine Lösung kommen bzw. zuerst Informationen über den Stack im Netz suchen und dann hier her zurückkehren.
Ende gut, alles gut
Und hier nun also die Antwort auf unsere eigentliche Frage: Probiert ein Prozess auf eine Adresse außerhalb seines Speicherbereichs, also, außerhalb eines Segmentes zuzugreifen, wird ein “Segmentation Error” erzeugt.
Beispiel: Betrachten wir das letzte Bild und nehmen an, das “bounds” Register des Heap und Stack Blocks beinhaltet 5, also ist jeder der beiden Blöcke jeweils nur 5 Einträge groß. Probiert jetzt ein Prozess auf die virtuelle Adresse 17 zuzugreifen, so erwischt dieser weder einen Heap Eintrag, da die höchste Adresse hier 15 ist, noch einen Stack-Eintrag, da dessen geringste Adresse hier 25 ist und einen Code-Eintrag sowieso nicht. Anstelle dass der CPU diesen Zugriff also zulässt und somit womöglich riskiert, dass ein Prozess Daten eines anderen klaut, löst er einen “Segmentation Error” aus, woraufhin das Betriebssystem den Prozess meist beendet.
Zum Schluss muss ich aber noch etwas beichten. Denn heutzutage verwendet eigentlich kaum ein System mehr Segmentierung (oft wird Paging stattdessen verwendet) weshalb ein Segmentation Error wie hier beschrieben eigentlich oft gar nicht mehr existiert. Der Begriff hat sich trotzdem gehalten – hat jedoch eine leicht andere Bedeutung bzw. tritt unter anderen Bedingen auf.